Introducción al ADN
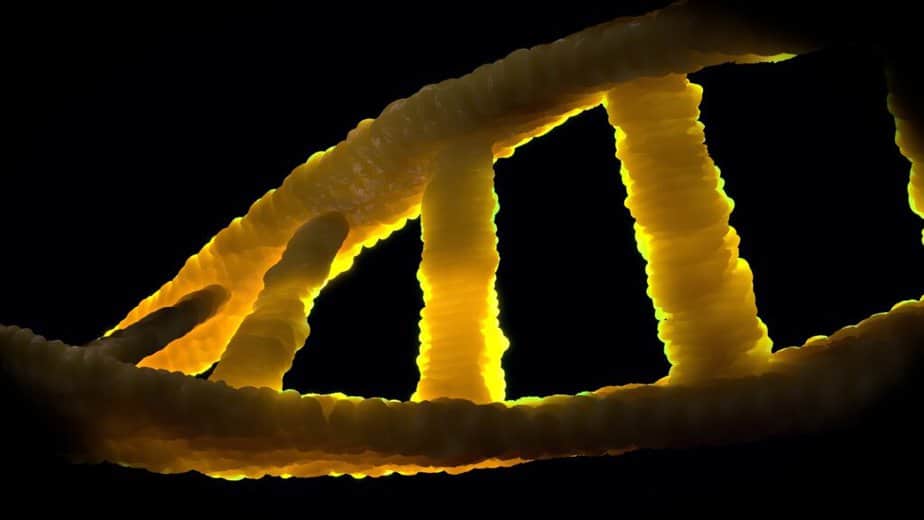
El ácido desoxirribonucleico es un ácido nucleico que es un polinucleótido compuesto por una cadena de muchos nucleótidos. La biomolécula ubicada en los cromosomas es portadora de información genética en todos los organismos vivos y en muchos virus (virus de ADN, pararetrovirus), es decir, la base material de los genes.
En estado normal, el ADN se construye en forma de doble hélice. Sus componentes básicos son cuatro nucleótidos diferentes, cada uno de los cuales consta de un residuo de fosfato, el azúcar desoxirribosa y una de las cuatro bases orgánicas (adenina, timina, guanina y citosina, a menudo abreviadas como A, T, G y C).
Los genes del ADN contienen la información para la producción de ácidos ribonucleicos. En los genes que codifican proteínas, este es un grupo de ARN importante, el ARNm. A su vez, contiene la información para la construcción de proteínas, que son necesarias para el desarrollo biológico de un ser vivo y el metabolismo en la célula. La secuencia de bases aquí determina la secuencia de aminoácidos de la proteína respectiva: el código genético codifica un aminoácido específico con tres bases adyacentes cada uno.
En las células de eucariotas, que también incluyen plantas, animales y hongos, la mayor parte del ADN del núcleo celular (núcleo latino, por lo tanto ADN nuclear o ADNn) está organizado como cromosomas. Una pequeña parte se encuentra en las mitocondrias, las «centrales eléctricas» de las células, por lo que se denomina ADN mitocondrial (ADNmt). Las plantas y las algas también tienen ADN en orgánulos fotosintéticos, los cloroplastos o plastidios (cpDNA). En bacterias y arqueas, los procariotas que no tienen núcleo celular, el ADN se encuentra en el citoplasma. Algunos virus, los denominados virus de ARN, almacenan su información genética en ARN en lugar de en ADN.
Editado por Christina Swords, Ph.D.
Estructura y organización del ADN
Bloques de construcción
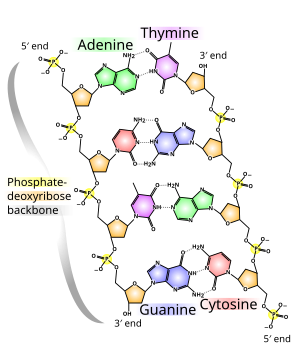
El ácido desoxirribonucleico es una molécula de cadena larga (polímero) formada por muchos componentes básicos llamados desoxirribonucleótidos o nucleótidos para abreviar. Cada nucleótido tiene tres componentes: ácido fosfórico o fosfato, el azúcar desoxirribosa y una base o nucleobase heterocíclica. Las subunidades de desoxirribosa y ácido fosfórico son las mismas para cada nucleótido. Forman la columna vertebral de la molécula. Las unidades de base y azúcar (sin fosfato) se denominan nucleósidos.
Los residuos de fosfato son hidrófilos debido a su carga negativa; dan al ADN en solución acuosa una carga negativa total. Dado que este ADN cargado negativamente disuelto en agua no puede emitir más protones, estrictamente hablando no es (ya no) un ácido. El término ácido desoxirribonucleico se refiere a un estado sin carga en el que los protones se unen a los residuos de fosfato.
La base puede ser una purina, a saber, adenina (A) o guanina (G), o una pirimidina, a saber, timina (T) o citosina (C). Dado que los cuatro nucleótidos diferentes difieren solo en su base, las abreviaturas A, G, T y C también se usan para los nucleótidos correspondientes.
Los cinco átomos de carbono de una desoxirribosa están numerados del 1 ‘al 5’. La base está unida al extremo 1 ‘de este azúcar. El residuo de fosfato se une al extremo 5 ‘. Estrictamente hablando, la desoxirribosa es 2-desoxirribosa; el nombre proviene del hecho de que, en comparación con una molécula de ribosa, falta un grupo hidroxi alcohólico (grupo OH) en la posición 2 ‘(es decir, ha sido reemplazado por un átomo de hidrógeno).
En la posición 3 ‘hay un grupo OH que une la desoxirribosa al átomo de carbono 5’ del azúcar del siguiente nucleótido a través de un enlace llamado fosfodiéster. Así, cada una de las denominadas hebras simples tiene dos extremos diferentes: un extremo de 5 ‘y un extremo de 3’. Las ADN polimerasas que sintetizan cadenas de ADN en el mundo viviente solo pueden unir nuevos nucleótidos al grupo OH en el extremo 3 ‘, pero no en el extremo 5’. Por lo tanto, la hebra única siempre crece de 5 ‘a 3’. Se suministra un nucleósido trifosfato (con tres residuos de fosfato) como un nuevo bloque de construcción, del que se separan dos fosfatos en forma de pirofosfato. El residuo de fosfato restante de cada nucleótido recién agregado se conecta al grupo OH en el extremo 3 ‘del último nucleótido presente en la hebra separando el agua. La secuencia de bases de la cadena codifica la información genética.
La doble hélice
El ADN normalmente se presenta como una doble hélice helicoidal en una conformación llamada B-ADN. Dos de los hilos simples descritos anteriormente están unidos entre sí en direcciones opuestas: en cada extremo de la doble hélice, uno de los dos hilos simples tiene su extremo 3 ‘y el otro su extremo 5’. Debido a la yuxtaposición, dos bases específicas siempre están opuestas entre sí en el medio de la doble hélice, están «emparejadas». La doble hélice se estabiliza principalmente apilando interacciones entre bases sucesivas de la misma hebra (y no, como se afirma a menudo, por enlaces de hidrógeno entre las hebras).
La adenina y la timina siempre están emparejadas, formando dos enlaces de hidrógeno, o citosina con guanina, que están conectados por tres enlaces de hidrógeno. Se forma un puente entre las posiciones moleculares 1═1 y 6═6 y, en el caso de emparejamientos guanina-citosina, adicionalmente entre 2═2. Dado que las mismas bases siempre están emparejadas, la secuencia de las bases en una hebra puede usarse para derivar las de la otra hebra, las secuencias son complementarias. Los enlaces de hidrógeno son casi exclusivamente responsables de la especificidad del emparejamiento, pero no de la estabilidad de la doble hélice.
Dado que una purina siempre se combina con una pirimidina, la distancia entre las hebras es la misma en todas partes, se forma una estructura regular. Toda la hélice tiene un diámetro de aproximadamente 2 nm y se enrolla más en 0,34 nm con cada molécula de azúcar.
Los planos de las moléculas de azúcar forman un ángulo de 36 ° entre sí, por lo que se logra una rotación completa después de 10 bases (360 °) y 3,4 nm. Las moléculas de ADN pueden volverse muy grandes. Por ejemplo, el cromosoma humano más grande contiene 247 millones de pares de bases.
Cuando las dos hebras individuales se retuercen juntas, quedan huecos laterales, de modo que las bases aquí están directamente en la superficie. Hay dos de estos surcos que se enrollan alrededor de la doble hélice (consulte las ilustraciones y la animación al principio del artículo). El «surco grande» tiene 2,2 nm de ancho, el «surco pequeño» sólo 1,2 nm.
En consecuencia, las bases en el surco grande son más accesibles. Por lo tanto, las proteínas que se unen al ADN de una manera específica de secuencia, como los factores de transcripción, generalmente se unen al surco grande.
Algunos tintes de ADN, por ejemplo DAPI, también se unen a un surco.
La energía de enlace acumulativa entre los dos hilos individuales los mantiene unidos. Los enlaces covalentes no están presentes aquí, lo que significa que la doble hélice del ADN no consta de una molécula, sino dos. Esto permite que las dos hebras se separen temporalmente en procesos biológicos.
Además del B-DNA que se acaba de describir, también hay A-DNA y un Z-DNA zurdo, que fue estudiado por primera vez en 1979 por Alexander Rich y sus colegas del MIT. Esto ocurre particularmente en secciones ricas en GC. No fue hasta 2005 que se informó de una estructura cristalina que muestra Z-DNA directamente en un compuesto con B-DNA y, por lo tanto, proporciona evidencia de la actividad biológica de Z-DNA. La siguiente tabla y la figura adyacente muestran las diferencias entre las tres formas en comparación directa.
Los apilamientos de la base no son exactamente paralelos entre sí como los libros, sino que forman cuñas que inclinan la hélice en una dirección u otra. La cuña más grande está formada por adenosinas emparejadas con timidinas de la otra hebra. En consecuencia, una serie de pares AT forma un arco en la hélice. Cuando tales series se suceden a intervalos cortos, la molécula de ADN asume una estructura curva o doblada, que es estable. Esto también se denomina difracción inducida por secuencia, ya que la difracción también puede ser inducida por proteínas (la denominada difracción inducida por proteínas). La difracción inducida por secuencia se encuentra a menudo en lugares importantes del genoma.
Cromatina y cromosomas
Cromosomas humanos en la metafase tardía de la división del núcleo de la célula mitótica: cada cromosoma muestra dos cromátidas, que se separan en la anafase y se dividen en dos núcleos celulares.
En la célula eucariota, el ADN está organizado en forma de hilos de cromatina, llamados cromosomas, que se encuentran en el núcleo celular. Un solo cromosoma contiene una doble cadena de ADN larga y continua (en una cromátida) desde la anafase hasta el comienzo de la fase S. Al final de la fase S, el cromosoma consta de dos cadenas de ADN idénticas (en dos cromátidas).
Dado que tal hilo de ADN puede tener varios centímetros de largo, pero el núcleo de una célula tiene sólo unos pocos micrómetros de diámetro, el ADN debe comprimirse o «empaquetarse» adicionalmente. En eucariotas, esto se hace con las llamadas proteínas cromatínicas, de las que destacan especialmente las histonas básicas. Forman los nucleosomas alrededor de los cuales se envuelve el ADN en el nivel de empaque más bajo. Durante la división nuclear (mitosis), cada cromosoma se condensa a su forma máxima compacta. Esto permite identificarlos particularmente bien bajo el microscopio óptico durante la metafase.
ADN bacteriano y viral
En las células procariotas, la mayoría del ADN de doble hebra en los casos documentados hasta ahora no está presente como hebras lineales con un comienzo y un final cada una, sino como moléculas circulares – cada molécula (es decir, cada hebra de ADN) cierra un círculo con sus 3 ‘y 5’ final. Estas dos moléculas de ADN circulares y cerradas se denominan cromosoma bacteriano o plásmido, según la longitud de la secuencia. En las bacterias, tampoco se encuentran en un núcleo celular, sino que están presentes libremente en el plasma. El ADN procariótico se enrolla en simples «superenrollamientos» con la ayuda de enzimas (por ejemplo, topoisomerasas y girasas), que se asemejan a un cable telefónico anillado. Al seguir girando las hélices alrededor de sí mismas, se reduce el espacio requerido para la información genética. En las bacterias, las topoisomerasas aseguran que la doble hebra trenzada sea arrancada en un lugar deseado cortando y reuniendo constantemente el ADN (requisito previo para la transcripción y replicación del ADN). Dependiendo del tipo, los virus contienen ADN o ARN como información genética. Tanto en los virus de ADN como en los de ARN, el ácido nucleico está protegido por una envoltura de proteína.
Propiedades químicas y físicas de la estructura de doble hélice del ADN
A pH neutro, el ADN es una molécula cargada negativamente, y las cargas negativas se encuentran en los grupos fosfato en la columna vertebral de las hebras. Aunque dos de los tres grupos OH ácidos de los fosfatos están esterificados con las respectivas desoxirribosas vecinas, el tercero todavía está presente y libera un protón a pH neutro, lo que provoca la carga negativa. Esta propiedad se utiliza en la electroforesis en gel de agarosa para separar diferentes hebras de ADN según su longitud. Algunas propiedades físicas, como la energía libre y el punto de fusión del ADN, están directamente relacionadas con el contenido de GC, es decir, dependen de la secuencia.
Interacciones de la pila de ADN
Dos factores principales son responsables de la estabilidad de la doble hélice: apareamiento de bases entre bases complementarias e interacciones de apilamiento entre bases consecutivas.
Contrariamente a la suposición inicial, la ganancia de energía a través del enlace de hidrógeno es insignificante, ya que las bases pueden formar enlaces de hidrógeno igualmente buenos con el agua circundante. Los enlaces de hidrógeno de un par de bases GC contribuyen sólo mínimamente a la estabilidad de la doble hélice, mientras que los de un par de bases AT incluso tienen un efecto desestabilizador. Las interacciones de pila, por otro lado, solo tienen efecto en la doble hélice entre los sucesivos pares de bases: entre los sistemas de anillos aromáticos de las bases heterocíclicas, se forma una interacción dipolar inducida por dipolo, que es energéticamente favorable. Así, la formación del primer par de bases es bastante desfavorable debido a la baja ganancia y pérdida de energía, pero el alargamiento (alargamiento) de la hélice es energéticamente favorable, ya que el apilamiento de los pares de bases tiene lugar bajo ganancia de energía.
Sin embargo, las interacciones de apilamiento son dependientes de la secuencia y energéticamente más favorables para GC-GC apiladas, menos favorables para AT-AT apiladas. Las diferencias en las interacciones de apilamiento explican principalmente por qué las secciones de ADN ricas en GC son termodinámicamente más estables que las secciones ricas en AT, mientras que los enlaces de hidrógeno juegan un papel menor.
Punto de fusión del ADN
El punto de fusión del ADN es la temperatura a la que se superan las fuerzas de unión entre las dos hebras simples y se separan entre sí. Esto también se llama desnaturalización.
Siempre que el ADN se desnaturalice en una transición cooperativa (que tiene lugar en un rango de temperatura estrecho), el punto de fusión es la temperatura a la que la mitad de las hebras dobles se desnaturalizan en hebras simples. De esta definición se derivan los términos correctos «punto medio de la temperatura de transición» Tm.
El punto de fusión depende de la secuencia de bases respectiva en la hélice. Aumenta si hay más pares de bases GC en la hélice, ya que estos son entrópicamente más favorables que los pares de bases AT. Esto no se debe tanto al diferente número de enlaces de hidrógeno formados por los dos pares, sino a las diferentes interacciones de apilamiento. La energía de apilamiento de dos pares de bases es mucho menor si uno de los dos pares es un par de bases AT. Las pilas de GC, por otro lado, son energéticamente más favorables y estabilizan la doble hélice con más fuerza. La relación entre los pares de bases de GC y el número total de todos los pares de bases viene dada por el contenido de GC.
Dado que el ADN monocatenario absorbe la luz ultravioleta aproximadamente un 40 por ciento más fuertemente que el ADN bicatenario, la temperatura de transición se puede determinar fácilmente en un fotómetro.
Si la temperatura de la solución cae por debajo de Tm, las hebras simples pueden reunirse entre sí. Este proceso se llama renaturalización o hibridación. La interacción de la desnaturalización y la desnaturalización se explota en muchos procesos biotecnológicos, por ejemplo, en la reacción en cadena de la polimerasa (PCR), las transferencias Southern y la hibridación in situ.
¿Te gustó esta publicación de blog? Puedes encontrar más publicaciones sobre ADN, genética y secuenciación aquí !
Es posible que le interesen las siguientes publicaciones de blog relacionadas:
Antes de irse, consulte nuestra secuenciación del genoma completo.