Introduction à l’ADN
L’acide désoxyribonucléique est un acide nucléique qui est un polynucléotide composé d’une chaîne de nombreux nucléotides. La biomolécule localisée dans les chromosomes est porteuse d’informations génétiques dans tous les organismes vivants et dans de nombreux virus (virus à ADN, pararétrovirus), c’est-à-dire la base matérielle des gènes.
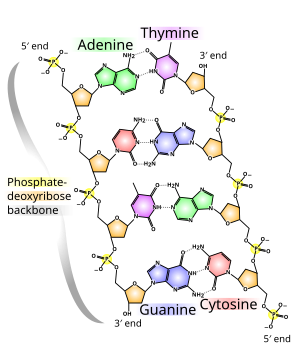
À l’état normal, l’ADN est construit sous la forme d’une double hélice. Ses éléments constitutifs sont quatre nucléotides différents, chacun composé d’un résidu phosphate, du sucre désoxyribose et de l’une des quatre bases organiques (adénine, thymine, guanine et cytosine, souvent abrégées en A, T, G et C).
Les gènes de l’ADN contiennent les informations nécessaires à la production d’acides ribonucléiques. Dans les gènes codant pour les protéines, il s’agit d’un groupe ARN important, l’ARNm. Il contient à son tour les informations pour la construction des protéines, nécessaires au développement biologique d’un être vivant et au métabolisme dans la cellule. La séquence des bases détermine ici la séquence des acides aminés de la protéine respective: Le code génétique code pour un acide aminé spécifique avec trois bases adjacentes chacune.
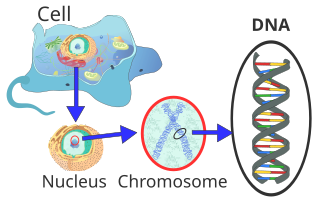
Dans les cellules des eucaryotes, qui comprennent également des plantes, des animaux et des champignons, la majorité de l’ADN du noyau cellulaire (noyau latin, donc ADN nucléaire ou ADNn) est organisée en chromosomes. Une petite partie se trouve dans les mitochondries, les «centrales électriques» des cellules, et est donc appelée ADN mitochondrial (ADNmt). Les plantes et les algues possèdent également de l’ADN dans les organites photosynthétiques, les chloroplastes ou les plastes (ADNc). Chez les bactéries et les archées – les procaryotes qui n’ont pas de noyau cellulaire – l’ADN est situé dans le cytoplasme. Certains virus, appelés virus à ARN, stockent leurs informations génétiques dans de l’ARN au lieu de l’ADN.
Edité par Christina Swords, Ph.D.
Structure et organisation de l’ADN
Blocs de construction
L’acide désoxyribonucléique est une molécule à longue chaîne (polymère) composée de nombreux éléments constitutifs appelés désoxyribonucléotides ou nucléotides. Chaque nucléotide a trois composants: l’acide phosphorique ou phosphate, le sucre désoxyribose et une nucléobase ou base hétérocyclique. Les sous-unités désoxyribose et acide phosphorique sont les mêmes pour chaque nucléotide. Ils forment l’épine dorsale de la molécule. Les unités de base et de sucre (sans phosphate) sont appelées nucléosides.
Les résidus de phosphate sont hydrophiles en raison de leur charge négative; ils donnent à l’ADN en solution aqueuse une charge globalement négative. Puisque cet ADN chargé négativement dissous dans l’eau ne peut plus émettre de protons, il n’est pas (plus) à proprement parler un acide. Le terme acide désoxyribonucléique fait référence à un état non chargé dans lequel des protons sont attachés aux résidus phosphate.
La base peut être une purine, à savoir l’adénine (A) ou la guanine (G), ou une pyrimidine, à savoir la thymine (T) ou la cytosine (C). Puisque les quatre nucléotides différents ne diffèrent que par leur base, les abréviations A, G, T et C sont également utilisées pour les nucléotides correspondants.
Les cinq atomes de carbone d’un désoxyribose sont numérotés de 1 ‘à 5’. La base est liée à l’extrémité 1 ‘de ce sucre. Le résidu phosphate est attaché à l’extrémité 5 ‘. Strictement parlant, le désoxyribose est le 2-désoxyribose; le nom vient du fait que, par rapport à une molécule de ribose, il manque un groupe hydroxy alcoolique (groupe OH) en position 2 ‘(c’est-à-dire qu’il a été remplacé par un atome d’hydrogène).
En position 3 ‘, il y a un groupe OH qui relie le désoxyribose à l’atome de carbone 5’ du sucre du nucléotide suivant via une liaison dite phosphodiester. Ainsi, chaque brin dit simple a deux extrémités différentes: une extrémité 5 ‘et une extrémité 3’. Les ADN polymérases qui synthétisent des brins d’ADN dans le monde vivant ne peuvent attacher de nouveaux nucléotides au groupe OH qu’à l’extrémité 3 ‘, mais pas à l’extrémité 5’. Le seul brin croît donc toujours de 5 ‘à 3’. Un nucléoside triphosphate (avec trois résidus de phosphate) est fourni en tant que nouveau bloc de construction, à partir duquel deux phosphates sont séparés sous forme de pyrophosphate. Le résidu phosphate restant de chaque nucléotide nouvellement ajouté est connecté au groupe OH à l’extrémité 3 ‘du dernier nucléotide présent dans le brin par séparation de l’eau. La séquence de bases dans le brin code les informations génétiques.
La double hélice
L’ADN se présente normalement sous la forme d’une double hélice hélicoïdale dans une conformation appelée ADN-B. Deux des brins simples décrits ci-dessus sont fixés l’un à l’autre dans des sens opposés: à chaque extrémité de la double hélice, l’un des deux brins simples a son extrémité 3 ‘, l’autre son extrémité 5’. Du fait de la juxtaposition, deux bases spécifiques sont toujours opposées l’une à l’autre au milieu de la double hélice, elles sont « appariées ». La double hélice est principalement stabilisée par empilement d’interactions entre les bases successives d’un même brin (et non, comme souvent revendiqué, par des liaisons hydrogène entre les brins).
L’adénine et la thymine sont toujours appariées, formant deux liaisons hydrogène, ou cytosine avec la guanine, qui sont reliées par trois liaisons hydrogène. Un pont est formé entre les positions moléculaires 1═1 et 6═6, et dans le cas d’appariements guanine-cytosine en plus entre 2═2. Comme les mêmes bases sont toujours appariées, la séquence des bases dans un brin peut être utilisée pour dériver celles de l’autre brin, les séquences sont complémentaires. Les liaisons hydrogène sont presque exclusivement responsables de la spécificité de l’appariement, mais pas de la stabilité de la double hélice.
Puisqu’une purine est toujours combinée avec une pyrimidine, la distance entre les brins est la même partout, une structure régulière se forme. L’hélice entière a un diamètre d’environ 2 nm et s’enroule encore de 0,34 nm avec chaque molécule de sucre.
Les plans des molécules de sucre sont à un angle de 36 ° les uns par rapport aux autres, et une rotation complète est donc réalisée après 10 bases (360 °) et 3,4 nm. Les molécules d’ADN peuvent devenir très volumineuses. Par exemple, le plus grand chromosome humain contient 247 millions de paires de bases.
Lorsque les deux brins individuels sont torsadés ensemble, des espaces latéraux restent, de sorte que les bases sont ici directement sur la surface. Il y a deux de ces rainures qui s’enroulent autour de la double hélice (voir illustrations et animation au début de l’article). Le « grand sillon » a une largeur de 2,2 nm, le « petit sillon » seulement 1,2 nm.
En conséquence, les bases du grand sillon sont plus accessibles. Les protéines qui se lient à l’ADN d’une manière spécifique à la séquence, comme les facteurs de transcription, se lient donc généralement au grand sillon.
Certains colorants ADN, par exemple le DAPI, se lient également à un sillon.
L’énergie de liaison cumulative entre les deux brins simples les maintient ensemble. Les liaisons covalentes ne sont pas présentes ici, ce qui signifie que la double hélice d’ADN ne se compose pas d’une molécule, mais de deux. Cela permet aux deux brins d’être temporairement séparés dans les processus biologiques.
En plus de l’ADN-B qui vient d’être décrit, il existe également l’A-ADN et un ADN pour gaucher, appelé Z-ADN, qui a été étudié pour la première fois en 1979 par Alexander Rich et ses collègues du MIT. Cela se produit en particulier dans les sections riches en GC. Ce n’est qu’en 2005 qu’une structure cristalline a été signalée qui montre l’ADN-Z directement dans un composé avec l’ADN-B et fournit ainsi des preuves de l’activité biologique de l’ADN-Z. Le tableau suivant et la figure ci-contre montrent les différences entre les trois formes en comparaison directe.
Les empilements de base ne sont pas exactement parallèles les uns aux autres comme des livres, mais forment des coins qui inclinent l’hélice dans un sens ou dans l’autre. Le plus grand coin est formé par des adénosines associées aux thymidines de l’autre brin. Par conséquent, une série de paires AT forme un arc dans l’hélice. Lorsque de telles séries se succèdent à de courts intervalles, la molécule d’ADN prend une structure courbe ou courbée, qui est stable. Ceci est également appelé diffraction induite par séquence, car la diffraction peut également être induite par des protéines (diffraction induite par les protéines). La diffraction induite par la séquence se trouve souvent à des endroits importants du génome.
Chromatine et chromosomes
Chromosomes humains dans la métaphase tardive de la division du noyau cellulaire mitotique: Chaque chromosome montre deux chromatides, qui sont séparées dans l’anaphase et divisées pour deux noyaux cellulaires.
Dans la cellule eucaryote, l’ADN est organisé sous la forme de fils de chromatine, appelés chromosomes, situés dans le noyau cellulaire. Un chromosome unique contient un long et continu double brin d’ADN (dans une chromatide) de l’anaphase au début de la phase S. À la fin de la phase S, le chromosome est constitué de deux brins d’ADN identiques (dans deux chromatides).
Etant donné qu’un tel fil d’ADN peut mesurer plusieurs centimètres de long, mais qu’un noyau de cellule n’a que quelques micromètres de diamètre, l’ADN doit être en plus compressé ou « tassé ». Chez les eucaryotes, cela se fait avec des protéines dites de chromatine, dont les histones de base sont particulièrement remarquables. Ils forment les nucléosomes autour desquels l’ADN est enveloppé au niveau de conditionnement le plus bas. Au cours de la division nucléaire (mitose), chaque chromosome est condensé à sa forme compacte maximale. Cela permet de les identifier particulièrement bien au microscope optique pendant la métaphase.
ADN bactérien et viral
Dans les cellules procaryotes, la majorité de l’ADN double brin dans les cas documentés jusqu’à présent n’est pas présente sous forme de brins linéaires avec un début et une fin chacun, mais sous forme de molécules circulaires – chaque molécule (c’est-à-dire chaque brin d’ADN) ferme un cercle avec ses 3 ‘et 5’ fin. Ces deux molécules d’ADN circulaires et fermées sont appelées chromosome bactérien ou plasmide, selon la longueur de la séquence. Chez les bactéries, ils ne sont pas non plus situés dans un noyau cellulaire, mais sont librement présents dans le plasma. L’ADN procaryote est enroulé en de simples « supercoils » à l’aide d’enzymes (par exemple des topoisomérases et des gyrases), qui ressemblent à un cordon téléphonique annelé. En faisant toujours tourner les hélices autour d’elles, l’espace requis pour l’information génétique est réduit. Dans les bactéries, les topoisomérases garantissent que le double brin torsadé est arraché à un emplacement souhaité en coupant et en rejoignant constamment l’ADN (condition préalable à la transcription de l’ADN et à la réplication de l’ADN). Selon le type, les virus contiennent de l’ADN ou de l’ARN comme information génétique. Dans les virus à ADN et à ARN, l’acide nucléique est protégé par une enveloppe protéique.
Propriétés chimiques et physiques de la structure en double hélice d’ADN
À pH neutre, l’ADN est une molécule chargée négativement, les charges négatives étant situées sur les groupes phosphate dans le squelette des brins. Bien que deux des trois groupes OH acides des phosphates soient estérifiés avec les désoxyriboses voisins respectifs, le troisième est toujours présent et libère un proton à pH neutre, ce qui provoque la charge négative. Cette propriété est utilisée dans l’électrophorèse sur gel d’agarose pour séparer différents brins d’ADN en fonction de leur longueur. Certaines propriétés physiques telles que l’énergie libre et le point de fusion de l’ADN sont directement liées à la teneur en GC, c’est-à-dire qu’elles dépendent de la séquence.
Interactions avec la pile d’ADN
Deux facteurs principaux sont responsables de la stabilité de la double hélice: l’appariement de bases entre bases complémentaires et les interactions d’empilement entre bases consécutives.
Contrairement à l’hypothèse initiale, le gain d’énergie grâce à la liaison hydrogène est négligeable, car les bases peuvent former des liaisons hydrogène tout aussi bonnes avec l’eau environnante. Les liaisons hydrogène d’une paire de bases GC ne contribuent que de manière minimale à la stabilité de la double hélice, tandis que celles d’une paire de bases AT ont même un effet déstabilisant. Les interactions d’empilement, par contre, n’ont d’effet que dans la double hélice entre paires de bases successives: Entre les systèmes cycliques aromatiques des bases hétérocycliques, il se forme une interaction dipolaire induite par les dipôles, ce qui est énergétiquement favorable. Ainsi, la formation de la première paire de bases est assez défavorable en raison du faible gain et perte d’énergie, mais l’allongement (allongement) de l’hélice est énergétiquement favorable, puisque l’empilement des paires de bases se fait sous gain d’énergie.
Cependant, les interactions d’empilement sont dépendantes de la séquence et énergétiquement les plus favorables pour le GC-GC empilé, moins favorables pour l’AT-AT empilé. Les différences dans les interactions d’empilement expliquent principalement pourquoi les sections d’ADN riches en GC sont thermodynamiquement plus stables que les sections riches en AT, tandis que la liaison hydrogène joue un rôle mineur.
Point de fusion de l’ADN
Le point de fusion de l’ADN est la température à laquelle les forces de liaison entre les deux brins simples sont surmontées et elles se séparent l’une de l’autre. Ceci est également appelé dénaturation.
Tant que l’ADN est dénaturé dans une transition coopérative (qui a lieu dans une plage de température étroite), le point de fusion est la température à laquelle la moitié des doubles brins sont dénaturés en simples brins. A partir de cette définition, les termes corrects « point médian de la température de transition » Tm sont dérivés.
Le point de fusion dépend de la séquence de base respective dans l’hélice. Il augmente s’il y a plus de paires de bases GC dans l’hélice, car celles-ci sont entropiquement plus favorables que les paires de bases AT. Cela n’est pas tant dû au nombre différent de liaisons hydrogène formées par les deux paires, mais plutôt aux différentes interactions d’empilement. L’énergie d’empilement de deux paires de bases est beaucoup plus petite si l’une des deux paires est une paire de bases AT. Les empilements GC, en revanche, sont énergétiquement plus favorables et stabilisent plus fortement la double hélice. Le rapport des paires de bases GC au nombre total de toutes les paires de bases est donné par le contenu GC.
Étant donné que l’ADN simple brin absorbe la lumière UV environ 40 pour cent plus fortement que l’ADN double brin, la température de transition peut être facilement déterminée dans un photomètre.
Si la température de la solution tombe en dessous de Tm, les brins simples peuvent se rejoindre. Ce processus est appelé renaturation ou hybridation. L’interaction de la dénaturation et de la renaturation est exploitée dans de nombreux processus biotechnologiques, par exemple dans la réaction en chaîne par polymérase (PCR), les transferts Southern et l’hybridation in situ.
Avez-vous aimé ce billet de blog? Tu peux trouver plus d’article sur l’ADN, la génétique et le séquençage ici !
Vous pourriez être intéressé par les articles de blog connexes suivants:
Avant de partir, consultez notre séquençage du génome entier!